
Table of Contents
The Fastest Path to Mastering LLMs
Most people use LLMs like digital books: they read, watch tutorials, and consume information without actively building. However, the fastest learners take a different approach — they experiment early, make mistakes, refine their understanding, and develop mental models through hands-on projects. True mastery comes from experiencing the complete lifecycle of an AI system, from the prototype to a production-ready application.
| Stage | Focus Area | Tools | Outcome |
| Beginner | NLP basics + prompts | ChatGPT, Claude | Understand outputs |
| Foundation | Transformers basics | HuggingFace | Model intuition |
| Intermediate | Fine-tuning concepts | LoRA, PEFT | Custom models |
| Advanced | RAG systems | LangChain | Real applications |
| Expert | Agent systems | AutoGen, CrewAI | Multi-agent workflows |
| Mastery | Production LLM systems | APIs + infra | Scalable AI products |
What many learners get wrong is spending months studying theory before interacting with real models. Practical understanding develops faster when learners begin experimenting with APIs and building small projects from the first week rather than waiting until they feel completely prepared.
What Does “Mastering LLMs” Actually Mean in 2026?
In 2023, mastering LLMs was often linked with writing better prompts and enhancing interactions with AI assistants. In 2026, the definition has expanded. True mastery now includes designing complete AI systems that combine models with retrieval, reasoning, memory, tools, and autonomous agents to solve intricate real-world problems.
LLMs are not chatbots anymore, but powerful cognitive engines that are enhanced by external knowledge, tools, and infrastructure. The key to mastering the model is knowing when to use the model, when to bring retrieval to the model, and when to put autonomous agents into the model.
This is an explanation for this journey in 5 levels of skills. In the Input Layer, there is a focus on prompt engineering and context design, which enables users to engage the AI effectively. The Model Layer explores the design of transformers, attention, and how LLMs generate outputs. Retrieval Layer adds techniques for utilizing external knowledge in models, such as RAG. Agent Layer highlights AI systems that can plan and operate, and perform multiple actions. Lastly, the Infrastructure Layer includes implementing and scaling secure LLM applications via APIs, cloud platforms, and production systems.
Also Read: Actionable Intelligence in 2026: The Definitive Guide to Turning Data Into Real Business Results
Core Mental Models Behind LLMs
Before you begin coding or exploring frameworks, understanding these four mental models will influence how you interact with LLMs and design AI applications.
Tokenization as compression
In a model, text is not stored as words; instead, it is segmented into sub-word chunks (tokens) that are a compromise between vocabulary size and coverage. For instance, the word “Tokenize” can have several tokens if the tokenizer is used. Knowing what a token is and how it relates to context limits, pricing, and text processing by models.
Probability-based generation
Each output token is a sample from a vocabulary distribution for the entire vocabulary. The model does not know the answers; it just continues the sequence of the input. This is why temperature is important, why different prompts will get different results, and why hallucinations occur.
Context windows as working memory
The context window is all the things the model can “see” at once, all the model’s working memory. Everything outside of the context is not part of the model. All three of the RAG, memory systems, and agent loops are used to deal with this basic constraint.
Embeddings as semantic maps
Similarity is translated into relatedness between words and sentences, in the form of high-dimensional vectors. These embeddings can be used to implement search, clustering, retrieval, and recommendation systems within LLM pipelines.

How LLMs Actually Work (Without the Math Overload)
Introduced in the 2017 paper “Attention Is All You Need,” the transformer architecture replaced many earlier sequential approaches, such as recurrent neural networks (RNNs), by allowing models to process relationships between tokens more efficiently through attention mechanisms.
When generating the word “Paris” in “The capital of France is ___”, the model will put high attention on the word “France” and “capital”, and low attention on the words “the” and “is”. This selective weighting allows transformers to capture relationships between distant parts of a sequence, making them highly effective for understanding complex language patterns.
| Feature | Training | Inference |
| Purpose | Learn patterns from data | Generate output for a prompt |
| Compute cost | Very high (thousands of GPUs) | Low–medium (single GPU/API call) |
| Data usage | Massive datasets (trillions of tokens) | User’s prompt + context window |
| Time | Days to weeks | Milliseconds to seconds |
The LLM Ecosystem: Models, APIs, and Frameworks
LLM development has moved beyond simply choosing the most powerful model. In 2026, developers must evaluate broader architectural decisions, including whether to use closed or open models and whether solutions should be hosted or self-managed. Closed models like GPT-4o, Claude, or Gemini are excellent for rapid prototyping and production use when quality reasoning is important, and they are faster to develop. Open models, such as LLaMA 3, Mistral, and Qwen, offer teams more flexibility, control, and privacy over their models.
In addition to models, frameworks, and their supporting technologies are increasingly crucial in the development of practical AI applications. LangChain and LlamaIndex allow developers to easily integrate models with data sources and build RAG-based applications and workflows; vector databases like Pinecone, FAISS, and Weaviate optimize semantic search and knowledge retrieval. The model itself is no longer the competitive differentiator, but rather how well they can create a system around the model that is competitive.
Prompt Engineering vs Context Engineering
While prompt engineering remains useful, modern AI development has expanded toward context engineering — designing the information, tools, memory, and instructions surrounding a model call. It’s now a field of context engineering: designing information, tools, and memory that go with a model call. A simple prompt combined with high-quality context is often more effective than a perfectly written prompt without relevant information, tools, or memory.

The characteristics of context engineering are knowledge (what the model knows about the domain), memory (what is remembered over time), tools (what the model can act on), and instructions (how the model should behave). Once you master all four, it’s the prompting that comes easily.
Building Real LLM Applications
Theory becomes meaningful when it is connected to practical implementation. Building real applications helps transform abstract concepts into lasting understanding.
| Application Type | Complexity | Real Example |
| Chatbots | Low | Customer support, FAQ assistant |
| RAG Systems | Medium | PDF Q&A, enterprise knowledge base |
| AI Copilots | High | Coding assistant, writing aid |
| Autonomous Agents | Very High | Workflow automation, research agents |
Retrieval-Augmented Generation (RAG): The Most Important Skill
The reason why LLMs hallucinate is that they give a plausible next sentence, rather than checking the facts. RAG overcomes this limitation in two ways: first, it provides the model with real-time, up-to-date information relevant to the domain at inference time, whereas the model was trained with previously fixed information; second, it enables the model to handle questions that go beyond the scope of its training data.
The architecture is elegant: insert a user query, run a search on a vector database for the most semantically similar document chunks, add them to a prompt to the model, and then let the model concatenate an answer that is supported by the source material.
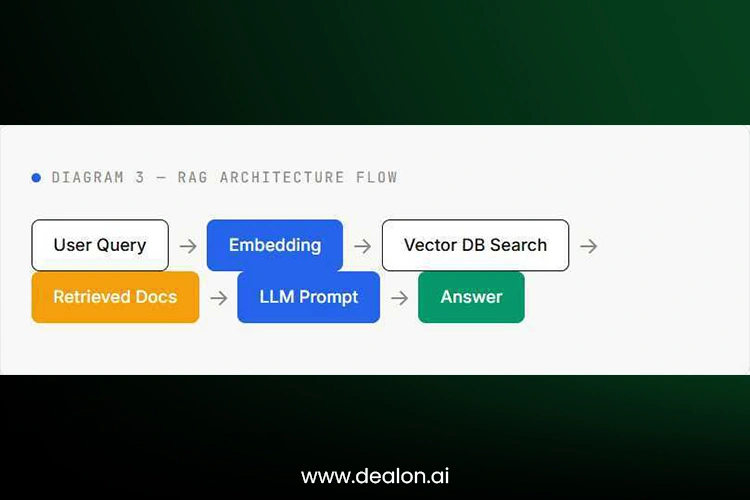
RAG is more than a technical method; it represents a different approach to designing AI systems by separating knowledge storage from reasoning. The LLM handles synthesis and interpretation, while external databases provide accurate and up-to-date information.
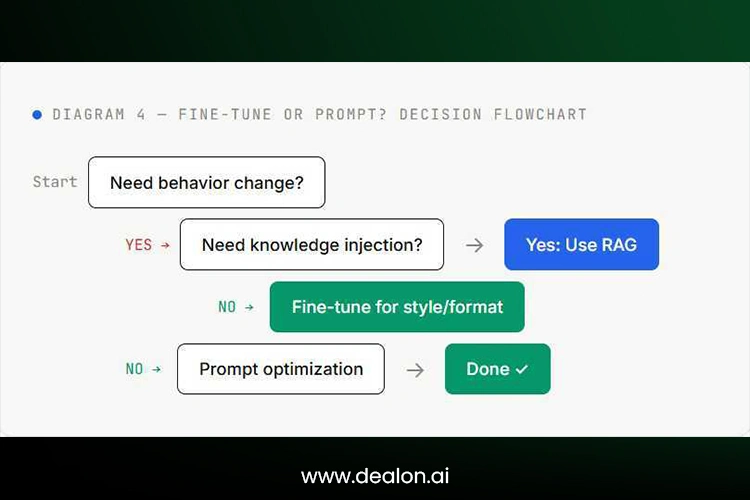
Fine-Tuning vs Prompting: When to Use What
In most cases, the first reaction is to fine-tune, and this is the wrong approach. Try prompt engineering and RAG first, and only train a custom model if those approaches aren’t effective. If the goal is to inject knowledge, RAG is the place to do it, but if the goal is to make style and format changes, then fine-tuning is the way to go.
With parameter-efficient methods such as LoRA and QLoRA, many 7B models can be fine-tuned efficiently on high-end consumer GPUs or cloud hardware.
LLM Agents and Autonomous Systems 2026 Perspective
An agent is an LLM-powered system that operates through an iterative loop: it plans actions, uses tools, observes outcomes, and adjusts its approach until it completes a defined objective.

Building agents is not as difficult as it sounds — in fact, the hardest part is reliability engineering. Agents can fail in unpredictable ways. Best practice for 2026 in the field: Keep the loops short, provide explicit stopping conditions for the models, and log all tool calls. Observability is the new debugging.
Common Mistakes When Learning LLMs
| 01 | Over-focusing on theory. Without reading papers, building projects gives a false sense of understanding. Code in the 1st week, not the 3rd month. |
| 02 | Ignoring context engineering. Focusing only on prompts while ignoring knowledge, memory, and tools is like improving one part of a system while neglecting the components that make the entire system work. |
| 03 | Misusing APIs. Failure to implement retry logic, to ignore rate limits, and not to cache similar calls — these actions kill production systems quickly. |
| 04 | Waiting to build projects. The LLM learning gap is ‘I understand how this works’ to ‘I can build something useful’. Close it early. |
| 05 | Fine-tuning before prompting. The vast majority of the possible use cases can be addressed through improved prompts and RAG. Fine-tuning is costly and might be done where it is not needed. |
Practical Learning Path: 30-Day Roadmap
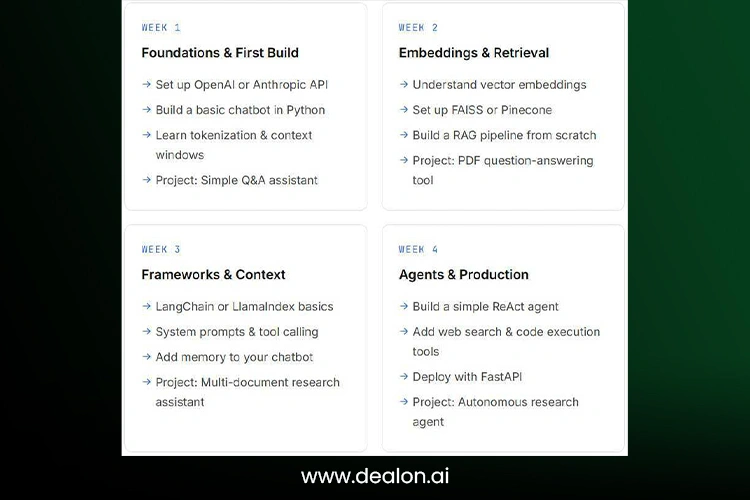
This 30-day roadmap helps learners progress from understanding LLM fundamentals to building practical AI applications.
For Week 1, concentrate on the basics: create an API for a service like OpenAI or Anthropic, get to know some of the basics like tokenization and context windows, and create a simple chatbot using Python to understand how interactions with an LLM work.
Week 2 will introduce embeddings and Retrieval-Augmented Generation (RAG), the methods by which AI systems can pull in external information. With the help of some tools such as FAISS or Pinecone, you can create a PDF question-answering application that enables an LLM to retrieve and utilize information from documents.
In Week 3, learn about application-building frameworks like LangChain or LlamaIndex. Understand the ability of AI to enhance its performance with system prompting, tool calling, and memory, and build an AI research assistant that can analyze and summarize information from multiple sources.
In week 4, continue developing into agent-based AI, creating a very basic React agent that is able to plan and execute tasks. Introduce capabilities such as web search and code execution capabilities, then deploy your app with FastAPI to grasp the process of building LLM systems in production.
By the end of this roadmap, learners will have theoretical knowledge and hands-on experience of creating modern LLM-powered apps.
Tools You Must Learn in 2026
The 2026 LLM development stack is now more organized, and a group of tools is behind most AI applications in the wild. The OpenAI API provides access to advanced language models that developers can integrate into software applications. Similarly, Hugging Face enables collaboration through open-source models, datasets, and machine learning workflows.
Applications such as LangChain can be used to coordinate model interactions, the use of tools, and application workflows. In contrast, LlamaIndex specializes in linking with external data via RAG pipelines for building AI applications. Embedding storage like Vector with Pinecone or FAISS allows for efficient knowledge retrieval as knowledge is stored and indexed in an embedding space.
Lastly, Python + FastAPI is a crucial pair for backend system development and deploying scalable AI-powered APIs. These tools are all essential components of the building blocks of workable and production-ready LLM applications in 2026.

The Future of LLM Mastery (2026–2030)
The future of LLM is beyond the use of one AI assistant to more independent, intelligent, and powerful systems. Agentic AI systems, with multiple AI agents working together to execute a workflow, will be one of the key application patterns between 2026 and 2027. Humans will not only be using AI tools but also will be creating the tools and guiding and appraising the designs.
The emphasis will be on self-improving models, which can improve based on feedback, generate training data, and continuously improve through real-world interaction between 2027 and 2028. AI systems will be more adaptive, minimizing the discrepancy between the building and the continuous improvement of models.
By 2028-2030, AI will be redefining software development. The use of AI in software development will increase in tasks like writing, testing, and maintenance, with human skills shifting towards more complex ones like system design, problem definition, and the assessment of AI-generated solutions. The writing of code for each line will become less important; the building of intelligent systems will be more important for the future of LLM mastery.
Frequently Asked Questions
How will mastering LLMs be realized?
It implies that you’re able to build, create, and deploy full LLM-powered systems instead of simply writing prompts. This encompasses comprehending model behavior, creating RAG pipelines, running agents, and deploying at model scale.
How long does it take to learn LLMs?
With dedicated efforts, you can create useful applications in 2-4 weeks. Frequent building for 3–6 months is required to reach production levels of reliability, optimization, and evaluation.
Is there a need for maths understanding for working with LLMs?
Not to develop applications. The following intuition is useful for research, but most practitioners do not use it at all, just at the API and framework level. Begin building, and then add math as much as one wants.
Can the beginners make LLM applications?
Yes. The APIs are easy to use, and most of the complexity is hidden in the frameworks. In less than 50 lines of Python code, you can create a simple OpenAI-powered chatbot. Start there.
What does RAG mean?
RAG (Retrieval-Augmented Generation) involves feeding the model relevant documents just before giving the answer, instead of providing answers that it learned during training. Consider it an open-book/closed-book exam.
Is fine-tuning necessary?
Very rarely, nearly always not as the initial step. Prompt engineering and RAG are most useful for most applications. Only fine-tune if you need a consistent style and format for the text, or if you require specific behavior for the text that you cannot achieve by using context engineering.
Which LLM should beginners start with?
Quality and clear documentation: Claude or GPT-4 as a good starting point. After getting comfortable with APIs, delve into HuggingFace’s open models and local deployment & customization.
What is an LLM agent?
An agent starts the LLM in a loop that takes it through a cycle of planning actions, invoking tools (search, execute code, APIs), observing the output, adjusting its plan, and redoing until it achieves a stopping criterion or returns a final answer.
